| << précédent | index |
L'objectif de ce TD est d'apprendre l'utilisation des techniques de data-mining, arbres de décision, réseaux de neurones, etc... Pour cela nous vous présentons un outil, Weka, qui permet de réaliser ces analyses. Dans un premier temps nous vous proposons de découvrir les comment utiliser Weka, puis vous aurez à exploiter ces nouvelles connaissances pour analyser vos propres données.
Travail évalué :
Rapport Data-minig à rendre sur l'analyse de vos données individuelles : exercice 4.
Weka est un logiciel gratuit qui permet de réaliser simplement des analyses de data-mining. Le logiciel comprend plusieurs outils dont un API (Aplication Programming Interface) qui permet d'utiliser les outils Weka dans d'autres programmes, un "Explorer" qui permet d'effectuer des analyses simples, et un editeur "KnowledgeFlow" qui permet de realiser des analyse plus complexes en modélisant le flux de données à travers les traitement à appliquer. C'est ce dernier outil que nous utiliserons.
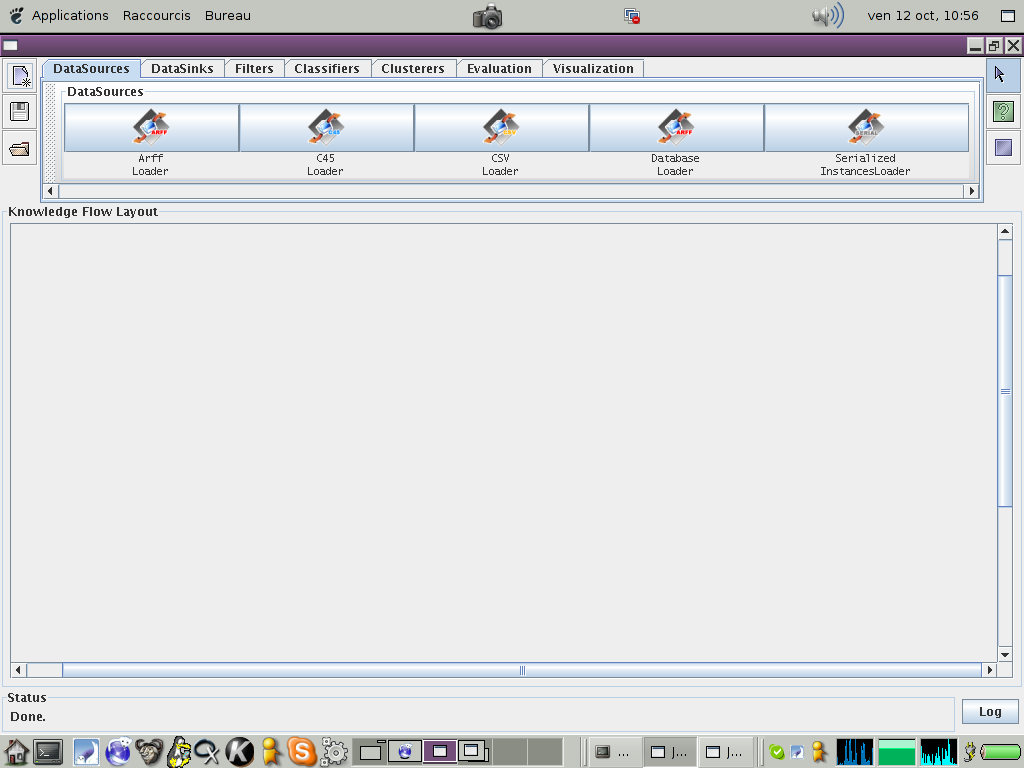
Voici à quoi ressemble l'interface Weka. En haut à gauche vous trouverez des icônes correspondant au menu "Fichier" standard : 'nouveau fichier', 'sauvergarder', 'ouvrir'. Puis vous avez la liste des modules utilisables dans la construction du flux de données. Ce modules sont :
La philosophie de ce "KnowledgeFlow" est de choisir les modules que l'on souhaite utiliser, et de les relier par des connections qui représentent des flux de données.
Attention: les connections sont typées : chaque module propose un ou plusieurs types de connection en sortie, et n'accepte qu'un certain type de connection en entrée. Un défaut de Weka est que les types de connection acceptés en entrée n'est pas explicite. Il faut donc apprendre qui accepte, voire requière, quel type de connection en entrée.
Dans la suite du TD nous vous apprendrons à utiliser Weka à partir d'exemples à reproduire.
Les regressions sont utilisées pour approximer des fonctions continues d'un variable de sortie en fonction des variables d'entrée : y = f(X). Le regression disponbiles se trouvent dans 'Classifiers/functions'.
Nous allons étudier deux jeux de données suivantes. Pour cela, téléchargez les données (strike.arff) et les données (cpu.arff) et sauvez les sur votre machine.
Maintenant lancez le programme Weka/KnowledgeFlow et suivez les instructions :
Dans 'DataSources' choisissez le module 'Arff Loader' et posez le sur l'espace de travail. Puis en cliquant sur le module avec le bouton droit de la souris vous pouvez le configurer (bouton droit, 'Edit/configure'), c'est à dire ici lui indiquer où se trouve le fichier de données .
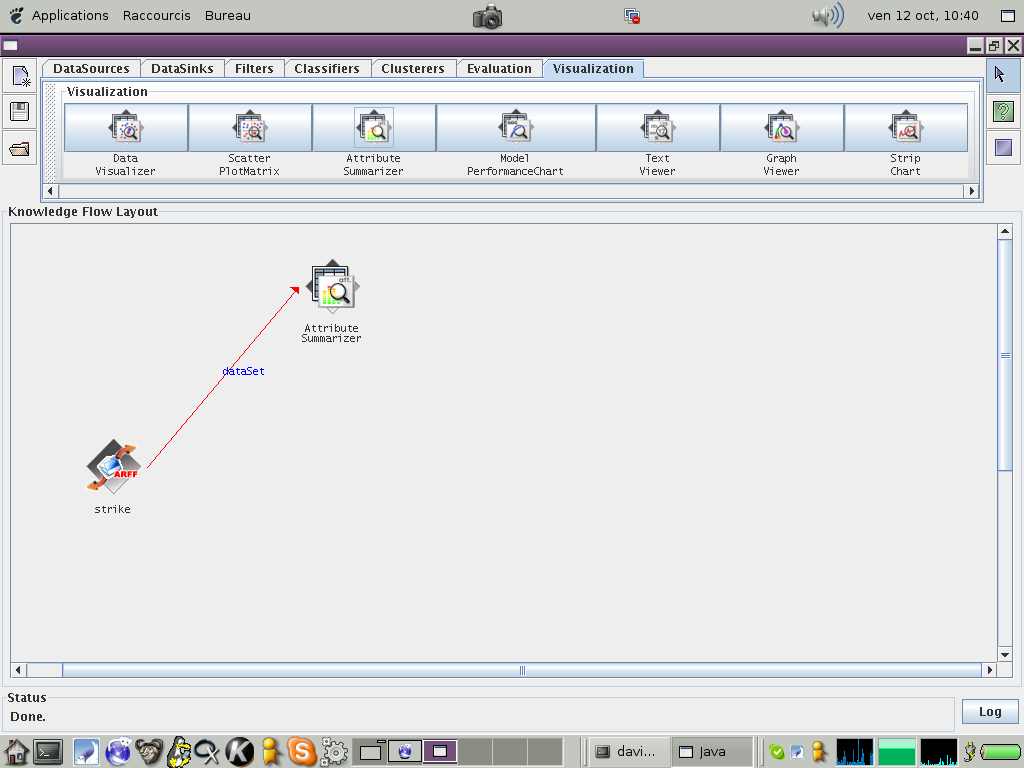
La première chose à faire est de visualiser ces données. Dans 'Visualization' choisissez le module 'Attribute Summarizer' et posez le sur l'espace de travail. Connectez les deux modules grâce à la connection 'dataset' que vous pouvez créer à partir du module 'Arff Loader' (bouton droit, 'Connections/dataset').
Votre espace de travail doit alors ressembler à ça. Il ne vous reste plus qu'à lancer l'analyse à partir du module de lecture des données (bouton droit, 'Actions/Start loading'). Vous pouvez alors voir les distributions des variables dans le module de visualisation (bouton droit, 'Actions/Show summaries').
Nous allons maintenant apprendre un premier modèle.
Dans 'Classifiers' choisissez le module 'Linear Regression' et posez à droite de votre espace de travail.
Pour être en mesure d'apprendre une regression il faut tout d'abord spécifier la variable dépendante. Cela se fait à l'aide du module 'Class Assigner' dans 'Evaluation'. Connectez ce modules avec les données à l'aide de la connection 'dataset'. Puis configurez le module. Cela consiste à donner l'indice de la variable dépendante. A la place d'indices numérique on peut utiliser les mots clés 'first' ou 'last', ce dernier étant la valeur par défaut.
Une fois la variable dépendante choisie il faut indiquer que nos données sont des données d'apprentissage. Pour cela on utilise le module 'Evaluation/TrainingSet Maker'. Connectez le au module 'Class Assigner' avec la connection 'dataset', et avec le module 'Linear Regression' avec la connection 'trainingset'.
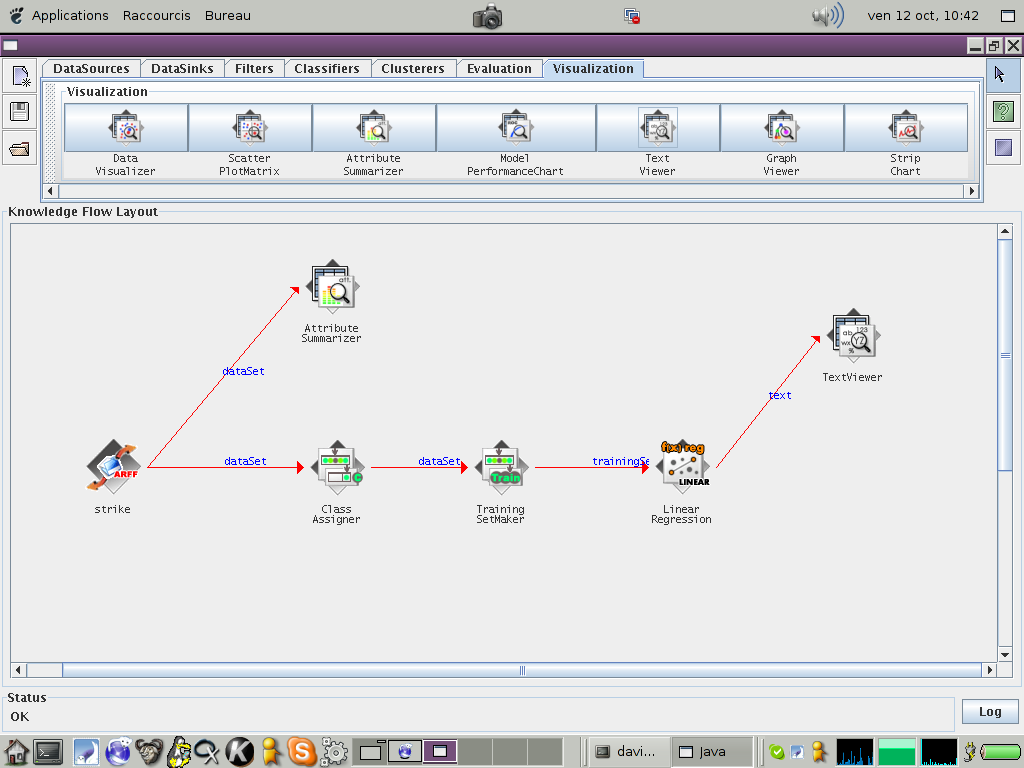
Enfin pour voir le modèle appris, ajoutez le module 'Visualization/Text Viewer' après le modèle, en le connectant avec la connection 'text'.
Votre espace de travail doit alors ressembler à celui-là. Activez l'apprentissage avec l'action 'Start Loading' du module de lecture des données, et regardez le modèle appris.
Maintenant nous allons évaluer la qualité de ce modèle. Pour cela il va falloir séparer les données en deux ensembles, un ensemble d'apprentissage et un ensemble de test.
Remplacez le module 'TrainingSet Maker' par le module 'Evaluation/TrainTest SplitMaker'. Connectez les deux connections 'trainingset' et 'testset' avec le modèle. La première connection permet d'apprendre le modèle comme précédemment. La seconde d'utiliser le modèle comme prédicteur sur les données de test et de comparer les prédictions à la valeur réelle dans les données.
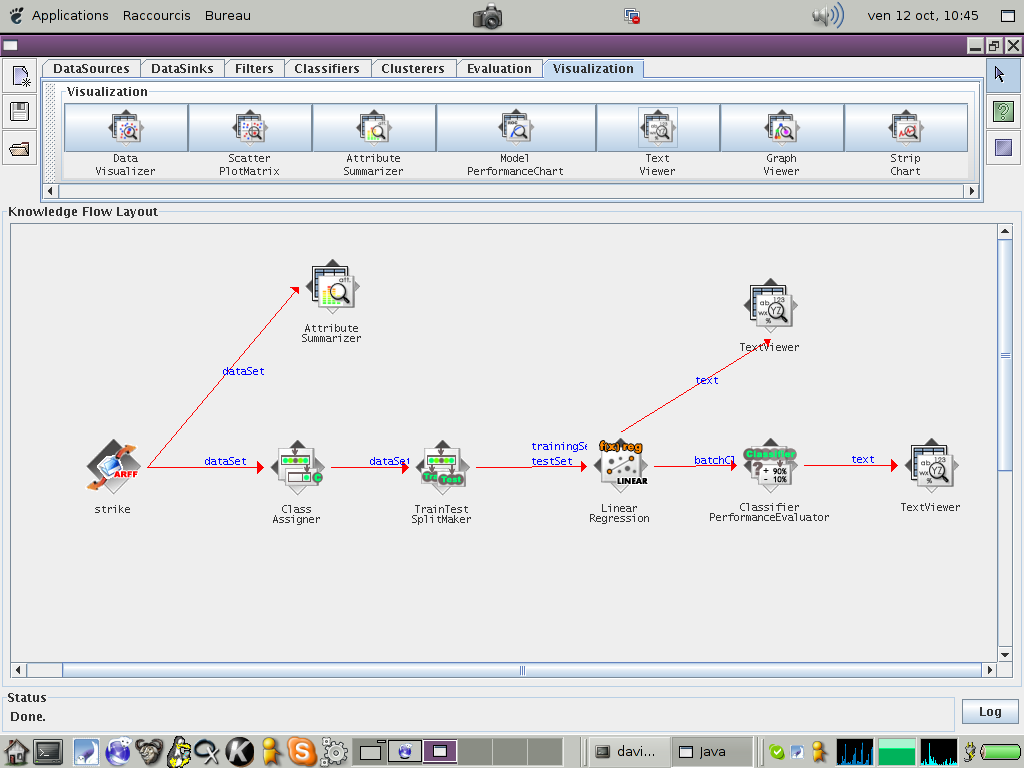
Pour evaluer le modèle il faut encore ajouter deux modules. Le module 'Evaluation/Classifier PerformanceEvaluator' et un module de visualisation textuelle. La connection a utiliser entre le modèle et le module d'évaluation est 'batchClassifier'.
Voici l'espace de travail résultant. Lancez l'analyse comme précédemment et allez consulter les performances du modèle. Ce modèle est-il bon ?
Nous allons maintenant comparer le modèle précédent avec un modèle semi-log-linéaire : log(y) = f(X).
Pour cela il nous faut tout d'abord appliquer une transformation sur la variable dépendante. Cela se fait avec le module 'Filters/Numeric Transform'. Connectez le directement aux données avec la connection 'dataset', et configurez le pour qu'il applique la fonction 'log' à la dernière colonne.
Ensuite vous pouvez dérouler la même chaine que précédemment. Pour comparer les résultats plus facilement utilisez le même module de visualisation pour les deux évaluations.
Votre espace de travail doit ressembler à cet example. Comparez les performances des deux modèles.
Vous connaissez maintenant le mode de fonctionnement de Weka. Vous pouvez sauvegarder votre espace de travail an deux temps à l'aide du bouton en haut à gauche. Il faut sauver votre schéma sous forme de fichier 'layout' (.kfml), et sa configuration (.kf). LA distinction entre les deux permet d'utiliser des architectures identiques avec des configurations différentes (changer le fichier de données, les paramètres des filtres ou des modèles, etc..).
Le principe de la catégorisation consiste à apprendre à ranger des éléments dans des catégories pré-définies en fonction de leur caractéristiques. Savoir attribuer automatiquement une catégorie à un élément peut être très utile : par exemple on peut attribuer une maladie à des patients en fonction de leur symptômes. Le principe est d'essayer de trouver le lien entre les caractéristiques des élements et la catégorie à laquelle ils appartiennent.
La catégorisation est une analyse supervisée. On connaît les caractéristiques et la catégorie d'un certain nombre d'éléments, et on essaye d'en déduire des règles de catégorisation automatique. On peut ensuite évaluer la catégorisation en comparant la classe préduite par un modèle et la classe réelle de l'élément.
Les arbres de décision sont un des outils les plus efficaces pour ce genre de tâches, c'est essentiellement eux que nous verrons ici. Mais d'autres modèles sont utilisables, notamment la regression logisitique ou bien les réseaux de neurones. Dans Weka tout ces modèles fonctionnent de la même ils les donc extrêmement facile de les comparer entre eux (en terme de performance).
Le premier exemple de catégorisation est un example classique tiré de la biologie : la catégorisation des espèces d'iris en fonction des dimensions des pétals et des sépales.
Telechargez les données iris.
Chargez les données comme précédement. Puis créer une chaine d'évaluation semblable à celle de la régression mais en utilisant le module 'Classifiers/trees/J48'. Et utilisez pour visualiser l'arbre générer le module de visualisation graphique 'Visualization/Graph' avec la connection 'graph'. (example)
Lancez l'analyse et regardez le graphe obtenu. Ansi que les performances de catégorisation. Deux élements sont importants. Le taux de succès qui indique le nombre d'erreurs, et la matrice de confusion qui indique qui a été bien catégorisé ou non et comment. Comment interprétez vous l'arbre obtenu ?
On utilise cette fois un catégorisation des champignons en commestible ou non à partir de la description de leurs caractéristiques.
Télechargez les données mushroom.
Utilisez la même architecture que précédement pour traiter ce problème. Regardez l'arbre obtenu, vous pouvez constater que chaque noeud possède de nombreuse branches, ce qui ne facilite pas forcément la lecture.
Il est possible de faire un arbre binaire simplement en choisissant l'option 'binarySplits=true' dans la configuration de l'arbre de décision.
Créez un chemin paralèlle avec un arbre de décision configuré en binaire, et comparez les arbres obtenus, et leurs performances. (example)
On va maintenant comparer les résultats obtenus par différents modèles sur des données plus complexes.
Telechargez les données credit-a.
Préparez une schéma permetteant la comparaison en parallèle des modèles suivant : 'Classifiers/trees/J48', 'Classifiers/function/Simple Logistic', 'Classifiers/functions/Multilayer Perceptron'. (example)
Comparez les performances relatives de ces trois modèles, et les informations qu'ils vous apportent sur les données.
La classification consiste à regrouper automatiquement en classes les données qui sont "similaires". L'objectif est de révéler la structure sous-jacente des données. Contrairement à la catégorisation les classes ne sont pas définies par l'exemple mais induite à partir de la notion de similarité utilisée, et d'un algoritme de création des classes. La classification est donc une analyse non supervisée.
La classification est une des techniques les plus puissantes du data-mining, mais aussi celle à utiliser avec le plus de précaution. Les résultats sont très dépends des choix de modèlisation (choix de la notion de similarité et de l'algorithme). Souvent il faut choisir arbitrairement le nombre de classe ex-ante, ce qui change aussi beaucoup les résultats.
Pour bien comprendre le principe de la classification nous allons utiliser des données simulées. Sur un plan en deux dimensions, nous avons générer automatiquement des points aléatoires autour de quatre centres. Il y a donc 4 classes dans nos données. La question étant de savoir si les algorithmes fournis dans weka permettent de les retrouver.
Télechargez les données clusters.
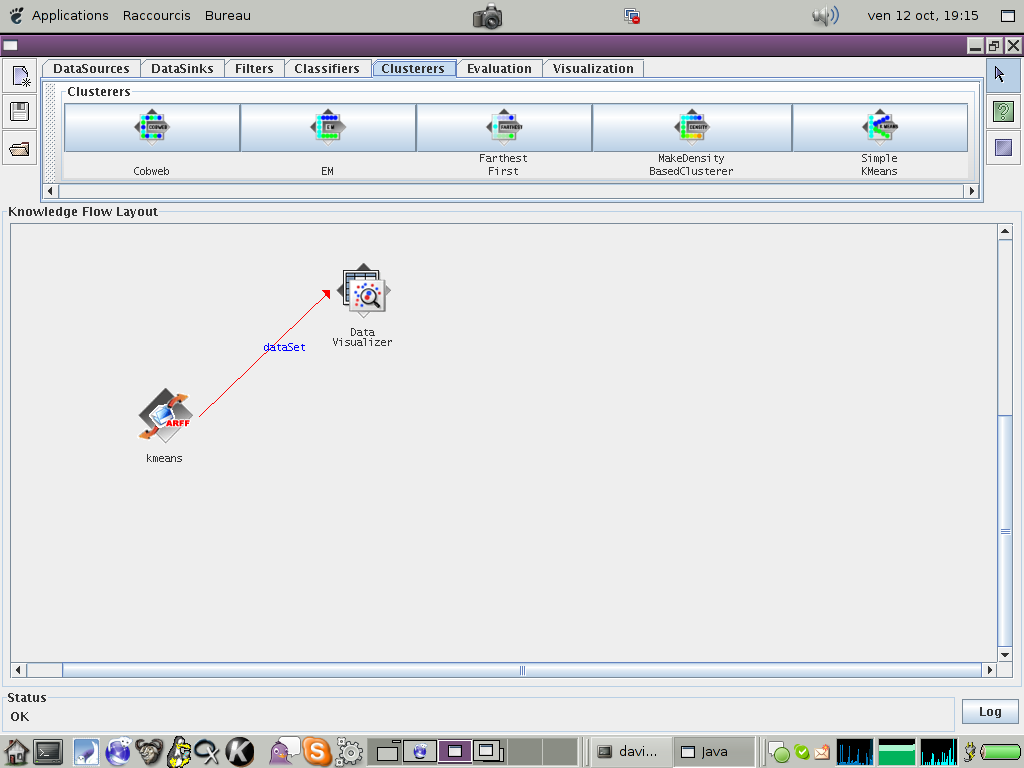
Tout d'abord visualisez les données avec le module 'Vizualisation/Data Visualizer'. Ce module permet de visualiser des nuages de points en deux dimensions, avec un code couleur pour la troisième dimension. (example)
Ensuite entrainez le module 'Clusterers/Simple Kmeans', en passant les données en 'trainingset' et en visualisant les clusters obtenus en mode texte. (example)
Lancez l'analyse et regardez la sortie produite. Que vous indique-t-elle ?
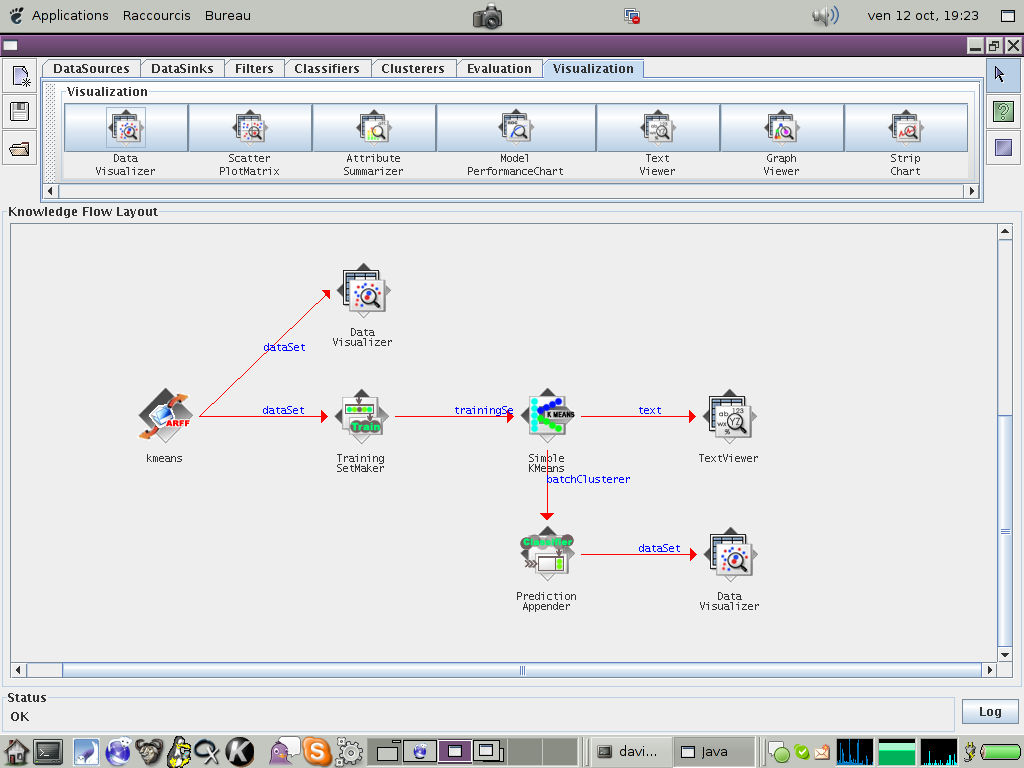
Il es possible de visualiser la sortie graphiquement en utilisant le module 'Evaluation/Predication Appender' qui ajoute la prédiction du modèle comme colonne des données (connection: batchClusterer). Si l'on regarde les données qui en sortent avec le 'Data Visualizer' on obtient alors notre nuage de point colorié en fonction de la classe attribuée par le modèle ! (example)
Par défaut le module des k-plus-proches-voisins génère deux classes. Que se passe-t-il si l'on passe à 3,4 ou 5 classes ? (example)
Maintenant remplacez le module 'Simple Kmeans' par le module 'Clusterers/EM'. Ce module fourni un algorithme de classification probabiliste, qui permet en plus de déterminer le nombre optimal de classes. Qu'obtenez-vous maintenant ?
Bien sûr dans la réalité les choses sont plus compliquées. Voici un exemple relativement simple de classification avec plus de deux dimensions et des données réelles.
Télechargez les données cities.
L'objectif ici est de classer les 48 plus grandes villes du monde en fonction de leurs indicateurs économiques : le salaire moyen, l'indice des prix et le nombre d'heures travaillées en moyenne.
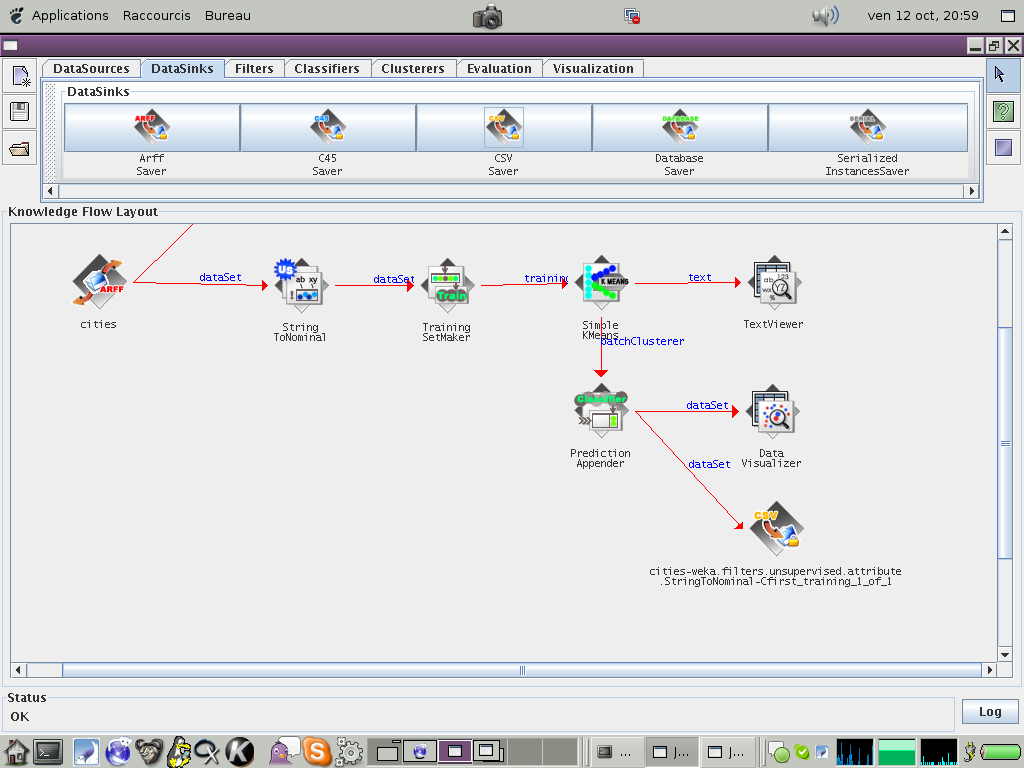
Utilisez le schéma précédent en ajoutant simplement le filtre 'Filters/String ToNominal' juste après le chargement des données. Afin de pouvoir juger de la pertinences des classes trouvées, il sera nécessaire d'observer les données produites, et pour cela il faut sauver les données classés en CSV pour les traiter sous excel. Ajoutez après le le module 'Prediction appender' un module de sortie 'DataSink/CSV Saver'. Configurer ce dernier afin de choisir dans quel répertoire sauver les données. (example)
Lancez l'analyse avec un classifier 'Simple Kmeans' et 6 classes. Observez d'abord les classes obtenus graphiquement. Ensuite ouvrez le fichier avec EXCEL, et triez les données en fonction de la classe assignée automatiquement. Ces classes vous semblent-elles avoir un sens ? Qu'est ce que cela vous inspire comme intérêt pour l'utilisation des classifieurs ?.
Vous pouvez maintenant travailler sur vos propres données .
Vos données sont stockées dans une base SQL, pour y accèder il faut utiliser le module 'DataSource/DataBase Loader'. Voici les élements à fournir pour la configuration :
Database URL: www.up2.fr
Username: votre-login
Password: votre-password
Query: la requête SQL pour lire vos données (ex: 'SELECT * from produits')
Key columns: laissez le champ vide
N.B: vérifiez que vous arrivez bien à charger vos données avant de continuer.
*** Exercice 4, à rendre sous forme de rapport
Attention: la variable achat doit être transformée de valeur numérique en classe discrète, utilisez pour cela le filtre 'Filter/Numeric ToBinary'
Indication: la requête à utiliser pour cette dernière analyse doit calculer le prix moyen et la qualité moyenne de tous les clients partageant les mêmes caractéristiques, par exemple ('SELECT AVG(qualite),AVG(prix) FROM visites as V JOIN produits as p ON p.ref = v.ref GROUP BY v.age, v.sexe, v.csp, v.style').
Important : dans tous les cas, fournir le schéma weka utilisé pour générer les analyses, les graphes pertinents (arbres de décision, clusters, etc.), et restituer les mesures de performances utilisées pour comparer les modèles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}